
英国数据伦理与创新中心(CDEI)发布了其关于隐私增强技术的应用指南测试版,旨在支持关于各种部署的决策。该指南使用了“基于问题和答案的决策树”格式,鼓励用户“探索哪些技术可能对他们的用例有益”。该指南中还包括了关于增强隐私的技术及其好处等方面。以下为其部分内容。
编译 | 吴宇昂
参考来源 | CDEI
背景
我们一直在研究隐私增强技术在确保数据安全性、私密性和使用可靠性方面的作用。新兴技术在保护隐私和机密的同时也会对有价值数据的共享和分析具有潜在的破坏性。为了充分实现数据的潜力,我们需要一个鼓励和促进有效采用这些技术的环境。为此,我们一直在调查PET在各个领域的使用情况,这将帮助决策者思考,如何在他们的数据项目中使用PET。
PETs是什么?
隐私增强技术(Privacy Enhancing Technologies,PET)是指保护敏感信息隐私或机密性的技术方法。这一宽泛的定义涵盖了一系列技术,从相对简单的广告拦截浏览器扩展到用于匿名通信的Tor网络。我们对范围更小的技术感兴趣,因此我们把这些技术分为两类:传统PETs和新兴PETs。
传统PETs是成熟的隐私技术,例如加密方案,以确保信息在传输和静止时的安全,以及去识别技术,如标记化和k-匿名。
新兴的PETs是一组已经开始为现代数据驱动系统中的隐私挑战提供新解决方案的技术。它并没有固定的定义,但在这里我们主要考虑五种技术:同态加密、可信执行环境、安全多方计算、差分隐私以及用于联邦数据处理的系统。
加密是用于保护信息的主要安全技术之一。加密将可读的数据转换成所谓的密文——一种人类或计算机无法读取的数据的表示形式。读取数据必须先对其进行解密,这需要访问适当的解密密钥。因此,数据对没有访问此密钥的每个人都是保密的。
传统PETs
1)传输中的加密和静止中的加密(Encryption in transit and at rest)
在传输过程中,当数据在两台相连的计算机之间流动时,加密可以保护数据的安全。例如,当你登录一个网站时,你的用户名和密码在通过互联网发送到有问题的网站之前会先被加密,确保一个窃听你连接的不良行为者无法了解你的凭据。
在静止状态下,加密可以保护存储在磁盘上的数据。例如,你可能正在使用一台将数据存储在加密硬盘上的电脑。这可确保存储在计算机上的数据无法被试图访问计算机的未经授权用户读取。
传输和静止加密是一种常见的成熟技术。当通过互联网发送信息和在磁盘上存储敏感信息时,它们应该被视为标准做法。
2)去识别技术(De-identification Techniques)
我们将去识别技术定义为任何数据转换或修改,其减少了关于数据集中个人或实体的信息量,也减少了个人或实体被重新识别的风险。这些方法与上面描述的PETs的区别在于,它们涉及对原始数据的直接操作,而不是在对底层数据保持最大效用的同时保护机密性的机制。
一些去识别技术的例子是:
编校(Redaction):删除整个记录或字段,或混淆部分记录或字段(例如,删除信用卡号的后四位)
标记化(Tokenization):用随机生成的值替换真实值
哈希(Hashing):将函数应用于值以产生固定长度的值(或哈希)
泛化(Generalization):将一个值转换为一个不太精确的值,例如将179cm的高度替换为170-180cm的范围
k-匿名(k-anonymity):应用反识别技术的组合,使数据集内的任何记录与(k-1)记录无法区分
新型PETs
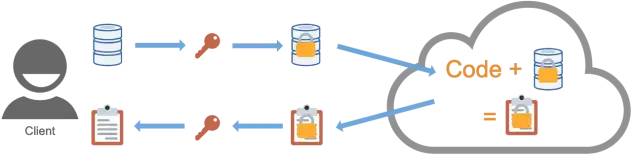
1)同态加密(Homomorphic encryption)
同态加密可以直接对加密数据进行计算。传统加密方案便于对传输中的和静止的数据进行加密,同态加密方案则便于对过程中的数据进行加密。
同态加密可以将数据处理外包给不受信任的第三方。数据控制者对其数据进行同态加密,将其发送给第三方数据处理者,处理者直接对加密数据进行计算,产生加密结果,然后将结果发送给控制者,由控制者对其进行解密。通过这种方式,敏感数据的处理可以外包给第三方,而无需建立信任,因为数据始终是加密的。
类似地,同态加密可以为组织在其不完全信任的计算环境中进行自己的数据处理提供保证,例如在使用云基础设施时。
同态加密方案根据方案允许的不同类型的操作可分为三类:
- 部分同态加密(Partial homomorphic encryption,PHE):只允许对加密数据进行单一类型的操作(如加法)。
- 某种同态加密(Somewhat homomorphic encryption,SHE):允许对加密数据进行一些运算组合(例如一些加法和乘法)。
- 全同态加密(Fully homomorphic encryption, FHE):允许对加密数据进行任意操作。
局限性考虑
FHE允许任意的操作,但是现有的方案通常是不切实际的,因为它们会产生巨大的计算开销。然而,这是一个活跃的研究领域,未来可能会发生改进。
尽管PHE和SHE方案性能更好,但它们只支持有限数量的操作,而且必须提前知道系统所需的操作的性质,以便选择适当的特定加密方案。
当外包给第三方数据处理者时,您应该注意这样一个事实,因为第三方不能读取任何数据,所以识别错误源或针对数据开发新代码可能会更加复杂。因此,您必须事先同意并遵守数据的模式。此外,您可能希望共享一个与实际数据集的模式匹配的纯文本虚拟数据集,第三方可以使用该数据集来开发和测试他们的代码。
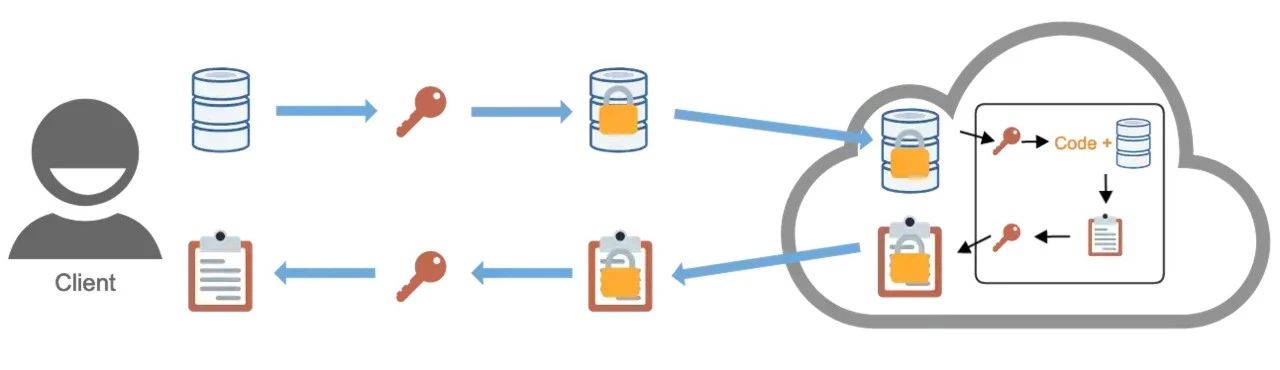
2)可信执行环境(Trusted Execution Environments)
可信执行环境(Trusted Execution Environment,TEE)是与计算机的主处理器和内存隔离的处理环境。客户端不能从主处理器访问此环境中保存的代码或数据,并且主处理器和TEE之间的通信是加密的。
TEE的用例与同态加密的用例类似。数据控制者可以将其数据存储在TEE中,由TEE中保存的不受信任的第三方代码进行操作。TEE内的处理直接发生在未加密的数据上——这意味着处理可能比同态加密要快,这是由于同态加密产生的计算开销。计算完后,在返回给数据控制者之前对结果进行加密,数据控制者有权访问适当的解密密钥。
局限性考虑
对于TEE仍然依赖于各方之间对环境设置正确的信任程度,并且与任何系统一样,始终存在一定程度的安全风险,例如通过侧向通道攻击,通过计算系统产生的信号推断TEE内发生的计算信息,比如功耗或内存利用率。
由于TEE是基于硬件的,因此很难修补它们的漏洞。例如,如果发现新的侧信道攻击向量,可能需要替换TEE的物理芯片以减轻威胁。
与TEE交互没有行业标准,每个供应商的TEE设计都是定制的。因此,利用TEE的应用程序必须根据TEE供应商的API进行编码,这可能导致供应商锁定。
3)多方计算(Multi-party computation)
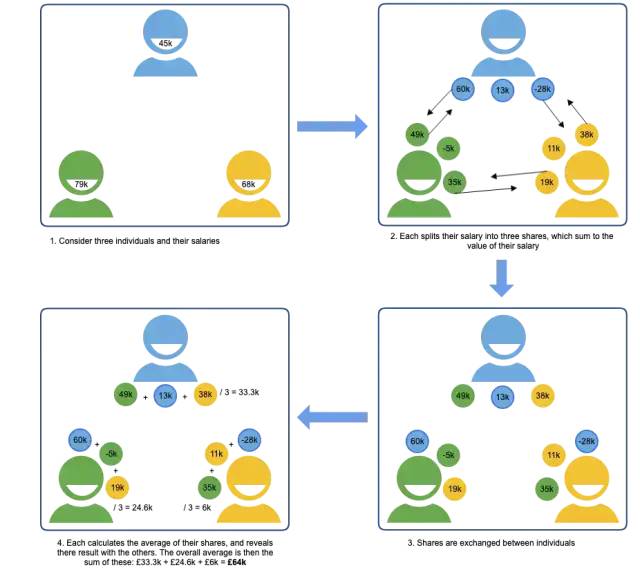
多方计算(Multi-party Computation,MPC)协议允许对来自多方的输入进行联合计算的功能,同时每个参与方对其他参与方的输入保密。这通常涉及到在多个网络节点上分割数据,比如每个节点承载一个“不可理解的分片”数据;对单个碎片的检查不会透露关于原始数据的信息。每个节点在其分片上计算一个函数,然后将结果聚合为最终结果。
为了直观地理解MPC,可以考虑一组员工,他们希望确定自己的平均工资,而不互相透露他们的个人工资。下图说明了如何使用加法秘密共享实现MPC,依赖加法的基本数学属性在双方之间分割计算,从而保持工资的机密性。将各方的计算结果重新组合,得到一个正确的结果。在实践中,MPC协议比这个简单的例子要复杂得多,它支持更安全,更广泛的操作。
局限性考虑
MPC协议通常不能扩展到通用的数据分析任务,这意味着协议必须针对手头的特定任务进行定制。
与在单个集中数据集上进行计算相比,节点之间相互通信的需求带来了通信开销。这意味着更复杂的协议需要节点之间进行更多的信息交换,在现实世界的设置中可能是不现实的(特别是在低延迟网络中节点不能共存的情况下)。
不当的串联方式可能会破坏MPC协议或从系统中泄漏信息——协议应该对任何此类攻击向量具有弹性。
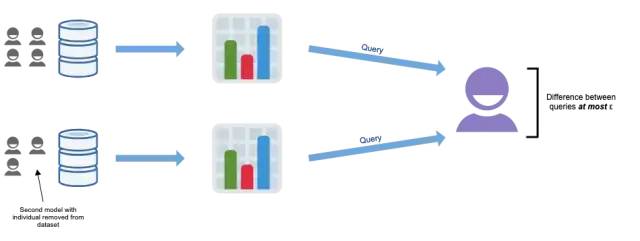
在某些情况下,MPC协议的输出可用于推断有关输入数据的信息。举个例子,想象一个系统,它可以计算出某一疾病检测呈阳性的个体的百分比。你也知道哪些人参与了这项研究。如果结果是60%,你不能确定哪些特定的个体是阳性的。然而,如果结果是100%,你肯定知道每个人都是阳性的——个人信息被泄露了。因此,了解网络中每个参与者所拥有的知识以及潜在结果的范围是非常重要的,这样才能采取措施将意外信息泄漏的风险降至最低。
4)差分隐私(Differential Privacy)
差分隐私是隐私的正式定义,要求任何统计分析的输出都不显示数据集中特定于个人的信息。算法通常通过将噪声添加到输入数据(局部差分隐私)或添加到其产生的输出(全局差分隐私)而具有差分私密性。
差分隐私是在2003年Irit Nisur和Kobbi Nissim的一篇论文的基础上发展起来的,这篇论文确立了信息恢复的基本法则:对一个统计模型的过多查询的过于精确的答案可以实现数据集恢复。因此,为了使用于构建模型的数据是私有的,模型在某种程度上必须是不准确的。必须仔细选择噪声的数量:太少,数据集不会是私有的;太多,输出将是不准确的,以至于无用。这是隐私和效用之间的权衡。
隐私-效用的权衡通过“Ɛ-差分”隐私的概念得以形式化。查询模型会泄漏关于数据集的信息,而信息泄漏的数量会随着查询的数量而增加。参数Ɛ量化了这种泄漏,称为隐私预算。如果用户超出预算,将停止执行进一步的查询。同样地,Ɛ可以被认为是对模型执行的查询结果与对模型执行的相同查询结果之间允许的最大差异,而该模型在数据集中忽略了个人数据。
局限性考虑
为隐私预算制定一个合适的有价值的预算常常是具有挑战性的,并且与上下文高度相关。
由噪声引起的不准确性在较小的亚种群中会更加明显。例如,批评美国人口普查局(US Census Bureau)利用差别隐私的人士辩称,这导致对当地人口统计数据的不准确理解,从而可能导致基于这些数据做出的政策决定对社区产生不利影响。
5)联邦分析(Federated Analytics)
联邦分析是针对分散数据执行计算机程序的一种范例。这包括一方将程序上传到数据所在的服务器或设备,在数据所在的服务器或设备上执行程序,并将结果返回给发起方。通过这种方式,没有数据直接泄露给当事人。
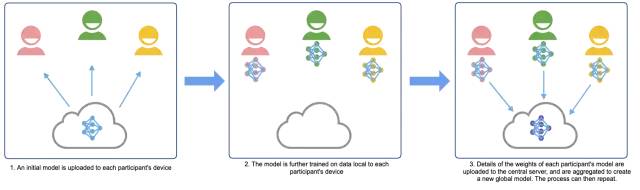
联邦分析的一个子集是联邦学习,它涉及到在分布式数据集上训练机器学习模型。其思想是使用本地数据直接在用户设备上训练本地模型,然后让设备彼此共享结果模型的权重,以确定新的全局模型。
这可以是集中式联邦学习,其中中央服务器负责协调参与设备的动作(如下所示),也可以是分散式联邦学习,参与其中的设备相互协调。无论哪种情况,其关键特性是用户数据永远不会离开设备,因为只有模型权重进行通信。
攻击者可以从这些权重中推断出用户信息,因此这一PET通常还会引入一些机制(如差分隐私)来减轻这种情况。
局限性考虑
尽管联邦分析没有提供对数据的直接访问,但是可以从分析的输出推断出数据集中个人的信息。以不同的私有方式执行分析是降低这种风险的一种方法。
不能直接访问数据会使开发、测试和故障排除代码变得更加困难。远程数据库使用的模式和标准的细节应该被共享,以帮助减轻这种情况,以及开发人员可以用来验证其代码功能的虚拟数据。
训练一个机器学习模型在计算方面是昂贵的,并且经常使用专门的硬件如gpu来加速。在联邦学习中,您可能无法控制将在其上执行训练的远程硬件,这可能会限制以这种方式构建的模型的类型。
PETs的价值:促进创新并保护隐私
隐私是一项基本权利。组织有义务保护隐私,在处理个人或敏感数据时必须考虑重要的法律、道德和声誉问题。CDEI关于公共部门数据共享的报告发现,这些担忧可能导致风险规避,从而妨碍数据以有益于社会的方式使用。PETs的使用可以帮助管理和减轻所涉及的一些风险。
因此,PETs可以成为创新的推动者,为有价值的数据共享和处理释放新的机会。此外,通过使数据共享和处理以一种更注重隐私的方式进行,PETs可以增强现有项目的隐私性。
如果相关风险过高,可能会阻碍或完全阻碍可能带来重大利益的数据项目。这可能是遵守数据保护法规相关的法律风险,或处理敏感客户信息相关的商业/声誉风险。如果应用得当,PETs可以在其保护的数据的隐私或安全级别上提供强有力的保障,从而大大降低敏感数据被披露的风险。PETs可以帮助天平向共享或处理数据的方向倾斜,使原本尚未开发的创新得以实现。
我们的研究发现,提高对PETs及其用例的认识和理解可以促进更大程度上采用这些技术。本指南旨在在这方面提供帮助,提出问题以帮助涉及敏感信息的数据计划的工作人员考虑哪些PETs可能是有用的。该指南的目的不是为了规定到牙齿,而是提供指向相关资源和用例的指导。这些资源和用例可能支持围绕使用PETs的决策制定。
PETs的挑战和局限性
PETs并不是灵丹妙药。单个PET不能完全解决数据驱动系统中固有的隐私挑战,并且PET应该作为更广泛的隐私设计的一部分应用,包括适当的访问控制、审计跟踪和信息治理安排。
“应用指南”中强调了特定PETs的一些技术限制,这些限制也在“什么是PETs?”页面。此外,在有效采用PETs方面可能会有更普遍的挑战,包括:
缺乏适当的技术专长:考虑到它们相对的新奇性和复杂性,组织可能需要专门的技术专长来有效地实施新兴的PETs。
财务成本:获取所需的专业知识和技术基础设施可能代价高昂。当开始采用PETs来推进项目时,应该进行适当的成本效益分析。
误用PETs:PETs可能引入透明度和问责风险,因为它们提供了新的秘密共享和处理信息的机制。不良行为者可能利用这一点,以有害或不道德的方式秘密使用数据。
PETs应用指南
下面的采用指南是一个以问题为基础的流程图,以帮助决策者思考在本网站上讨论的PETs中有哪些方面可能对他们的项目有用。
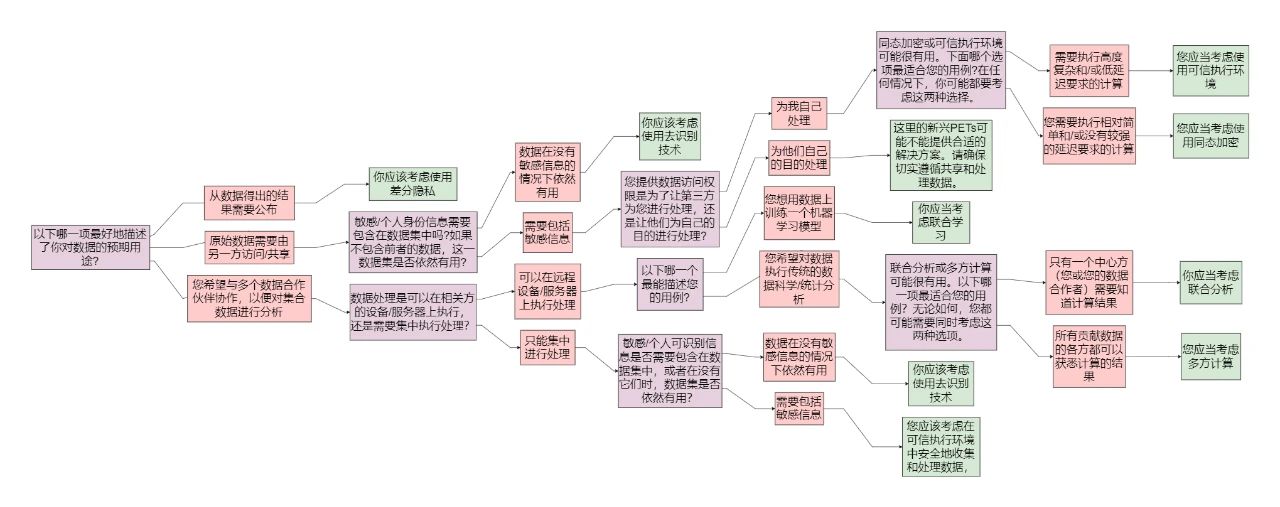
该指南的目的不是过分规定,也没有声称涵盖了所有的PETs用例。相反,它通过帮助用户探索哪些技术可能对他们的用例有益,来寻求以PETs所支持的范围进行决策制定。一个特定的PET是否提供了合适的解决方案将取决于具体的环境,指南的结果应该作为探索的建议而不是最终的解决方案来阅读。
理解一下这点同样重要:除非伴随着良好的总体隐私设计和适当的治理安排,否则使用单个PET本身并不能保证隐私的改善。您可以在这里探索共享和处理数据的良好实践:

